Hasta ahora, el cálculo de Malliavin ha sido principalmente un juego o procedimiento que aplicamos a procesos estocásticos. Profundicemos más y obtendremos a algunos resultados interesantes.
Derivada de Malliavin del proceso de Ornstein-Uhlenbeck
Supongamos un proceso aleatorio \(N_t\) que fluctúa alrededor de un valor \(\mu\) y se corrige a sí mismo con mayor intensidad mientras mayor sea la distancia a \(\mu\), más algo de ruido. En términos de ecuaciones, queremos algo como esto:
\[
dN_t = \theta(\mu - N_t)\,dt+ \sigma\,dW_t
\]
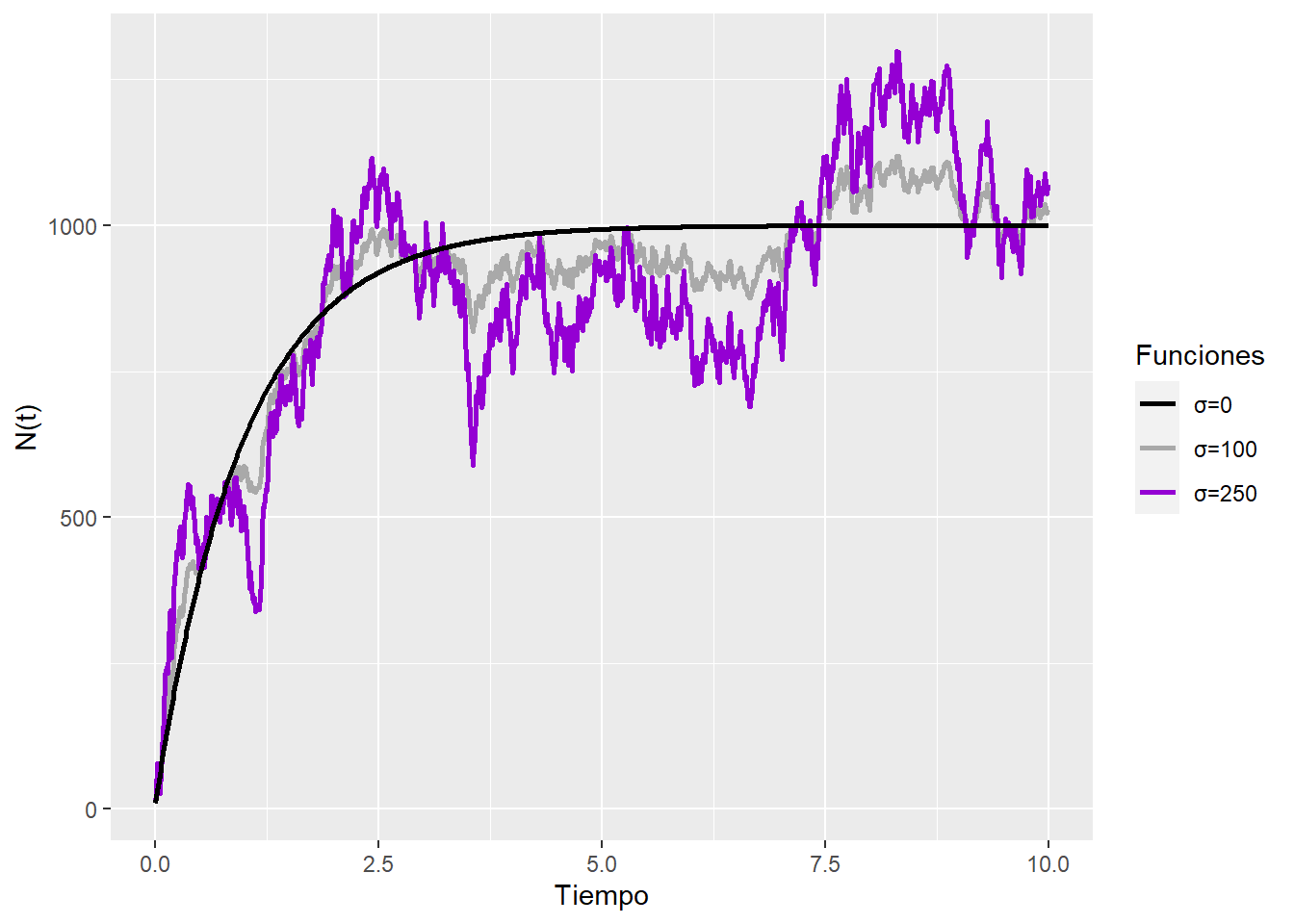
Por ejemplo, digamos que un lago puede albergar alrededor de \(\mu=1000\) truchas. Si hay más que eso, algunas morirán de hambre y, si hay menos, se reproducirán. Finalmente, \(\theta\) controla cuán fuerte es la corrección. A continuación, se muestran algunas trayectorias poblacionales con \(\theta=1\) y diferentes valores para \(\sigma\):
Este es un proceso muy común, tanto que ya tiene un nombre propio: el proceso de Ornstein-Uhlenbeck. Ahora, calculemos su derivada \(DN\). Tenemos \(a(X) = \theta(\mu - X)\) y \(b(x) = \sigma\), por lo que no es un proceso de Ito sencillo que solo depende del tiempo. Es mejor comenzar con ellos antes de abordar el proceso de Ornstein-Uhlenbeck.
Recordemos que podemos dividir las integrales como \(\int_0^t... dW_t=\sum_{i=1}^n{ ...(W_{t_i}-W_{t_{i-1}})}\). Entonces, podemos transformar un proceso de Ito clásico \(X_t\) en algo a lo que podemos aplicar fácilmente las reglas de la cadena y del producto para la derivada de Malliavin:
Se ve un poco caótico, pero todo es como podríamos esperar: \(t\) es el valor terminal de ambas integrales, \(s\) es la variable que usamos para integrar de \(0\) a \(t\), y \(r\) es la variable que introdujimos con la derivada de Malliavin. La expresión tiene sentido: la influencia de \(\sigma\) en el proceso de Ito es la misma a lo largo de todo el recorrido del proceso de Ito.
Ahora, usamos un argumento similar para la cantidad de truchas en el lago, que evoluciona según un proceso de Ornstein-Uhlenbeck. Dado que \(\mu_s\) y \(\sigma_s\) son ahora \(a(s,X_s)\) y \(b(s,X_s)\), aplicamos las reglas de la cadena y del producto como se indicó anteriormente para llegar a:
Ahora, sabemos por lo anterior que \(\frac{\partial a}{\partial x} = -\theta\) y \(\frac{\partial b}{\partial x} = 0\), entonces reemplazamos y, suponiendo que sabemos resolver ecuaciones integrales, resolvemos:
En este caso, llegamos a una expresión linda que nos dice algo interesante: el efecto de una perturbación en el número de truchas es exponencialmente menor si \(r<<t\). Esto tiene sentido: la población de truchas \(N\) quiere estar cerca de \(\mu\) y la población de un pasado lejano es irrelevante. También nos dice que no hay aleatoriedad en la fluctuación porque no depende de una variable aleatoria como \(W_t\).
Finalmente, tuvimos suerte arriba. \(D_rN_t\) es simple y pudimos escribir una solución en forma analítica. Si fuera más complicada, probablemente sea mejor estimar una solución. Alos (2021) hace un gran trabajo mostrando lo anterior.
Fórmula de Clark-Ocone-Haussman
Veamos una aplicación relativamente simple con implicaciones muy profundas, siguiendo completamente el planteo descripto en Friz (2002). Consideremos esta función:
Esta función es una martingala exponencial, es decir, \(\mathbb{E}_s[F(t)]=F(s)\). A continuación, tomamos \(F(1) = \mathcal{E}(h)\) y calculamos \(DF\) :
Ahora bien, esto sólo es válido en \(t=1\), pero podemos usar el operador de esperanza y la propiedad de las martingalas para obtener los valores en un tiempo anterior. Llamaremos \(\mathcal{F}_s\) a la filtración hasta el tiempo \(s\) (la forma a la que llamamos a la “historia” o “información” conocida hasta el tiempo \(s\)), y luego:
Por último, esta martingala \(F(t)\) es la solución de la ecuación diferencial (estocástica) \(dF(t) = h(t)F(t)dB_t\), cuando \(F(0)=1=\mathbb{E}[F]\). Reemplazando con la expresión anterior obtenemos:
Esta es la fórmula de Clark-Ocone en todo su esplendor. Nos permite calcular en forma explícita lo que el Teorema de Representación en Martingala indicaba que debía existir. La derivada de Malliavin es el ingrediente clave para tener una expresión analítica y es la razón principal por la que a uno le interesaría. La expresión nos afirma que cualquier variable aleatoria indexada por el tiempo \(F_t\) se puede dividir en una suma de una parte “determinista” (su esperanza matemática), y una martingala que fluctúa alrededor de ella.
Podemos aplicar esto al proceso de Ornstein-Uhlenbeck para nuestra población de truchas. Sabemos de antes que \(D_rN_t = \sigma\,e^{-\theta(t-r)}\). Vemos que no hay \(W_t\), por lo que la esperanza es la derivada de Malliavin, directamente. Podríamos estimar el valor de \(\mathbb{E}[N]\) o intentar resolver la ecuación diferencial (estocástica), pero dado que el proceso ya tiene una solución conocida, voy a ahorrarnos el esfuerzo y usarla directamente. Aquí está la aplicación de Clark-Ocone para un proceso de Ornstein-Uhlenbeck:
¿Por qué nos importa esto? Bueno, si quisiéramos simular diferentes trayectorias de nuestra población de truchas \(N\), solo necesitamos simular la martingala, y la parte determinista solo se calcula una vez. En segundo lugar, podemos usar la fórmula de Clark-Ocone para calcular directamente la varianza para \(N\), sin conocer la solución analítica completa que usamos arriba. Recordemos que \(\mathbb{Var}[N]=\mathbb{E}[N-\mathbb{E}[N]]^2\), entonces, usando la isometría de Ito:
Tengamos en cuenta que esto funciona para cualquier variable: solo se necesita la derivada de Malliavin para obtener la varianza. Vemos arriba que:
Nuestra población de truchas \(N\) en el largo plazo (\(t \rightarrow \infty\)) será un proceso que se mueve alrededor de \(\mu\) con una varianza constante \(\frac{\sigma^2}{2\theta}\)
La varianza en el momento de la introducción de las truchas al lago (\(t \approx 0\)) es muy pequeña porque el crecimiento de \(N\), que intenta alcanzar \(\mu\) lo antes posible, predomina por encima del ruido normal del proceso
Un \(\theta\) grande no solo hará que la varianza de largo plazo llegue antes, sino que también evitará grandes desviaciones de \(\mu\) en el largo plazo
Alos, & Lorite, E. 2021. Malliavin Calculus in Finance: Theory and Practice (1st ed.). 1.ª ed. Financial Mathematics Series. Chapman; Hall/CRC. https://doi.org/10.1201/9781003018681.